In this article, we will explore the use of caching in system design interviews. Caching is a powerful tool being used in modern application and having a clear understanding of caching will help you in your system design interviews, especially for scaling and throughput improvements.
What You will Learn?
Caching in System Design
Caching is one of the key technique for scaling your application. Keep in mind caching in system design interview is a powerful tool. We learned how we can use load balancer to scale our application horizontally, caching can increase both performance and scalability with lesser cost than some other techniques used for scaling the application. Caching is like a short-term memory with limited space, but it’s quick to access the data from the cache. It’s way easier to add caching layer to an existing application and often used as the first step to scale the application or improve the latency.
1. What is Caching
Caching is a short-term memory and a kind of storage layer that we can add between our application serving the end customer and the original data source. One of the example is the cache layer between the application server and the underlying data source, e.g. database or remote web application.
- Data requested by the application, in our case, it’s our application server.
- Application server check the cache, if the data is there in the cache, it returns the data without going to the original source.
- If no data is found in the cache, it will retrieve the data from the source (e.g. database), store in the cache for next time and return the data back to the calling client.
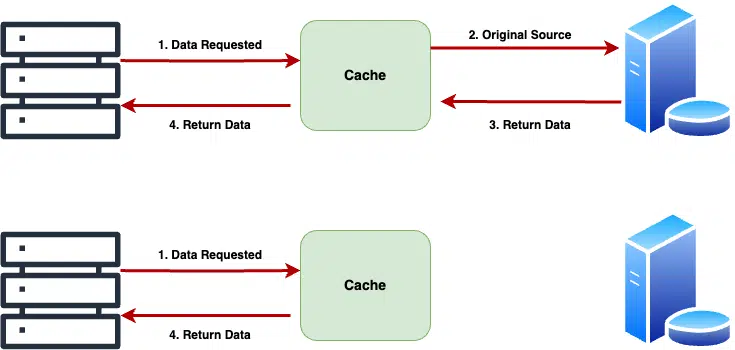
As seen in the above image, we fetched the data first time from the source and stored in the cache before returning to the application. Instead of fetching data from its source or generating a response each time it is requested, caching builds the result once and stores it in cache. Subsequent requests are satisfied by returning the cached result until it expires or is explicitly deleted. In modern application, caching can be used a multiple places. Here are some examples to start with:
- Web servers (Apache or NGINX etc.)
- Database queries.
- API Response Cache
- Static content (e.g. JavaScript, CSS etc.) caching.
- Images and video content caching.
- HTML Pages caching.
2. Why Caching?
As I told earlier, caching is an important tool during your system design interview, so let’s try to get an answer to the following question “Why is caching important?“
Caching is a crucial when working on the system performance and user experience. For web applications, caching plays a critical part is page load speed. Caching allows us to server the client requests without even calculating the response (it’s served directly from the cache) which helps in.
- Scaling Application easier.
- Improve operational Latency.
- Reduce response time.
Let’s go through some details to understand why caching is so important
2.1 Customer Experience
How will you like any application which takes ages to load? Will you continue to wait for the application to load? By serving the response from cache, we reduced the response time and latency, thus improving the customer experience. Keep in mind that application which load fast is always preferred by the customer. How many times you have seen YouTube or Facebook taking longer to load?
2.2. Scalability
By adding caching layer, we can reduce the load on the origin server which contains the data. This can help us scale the systems by reducing the number of requests reaching the origin server. This frees up resources on the origin server, allowing it to handle other tasks more efficiently. Can you image what will happen if every request going to the server to get data copy?
2.3. Faster Response Time
Retrieving data from cache is much, much faster than getting it from the original server. When we get the data from cache, it served with no additional processing, thus improving the overall response time. Getting data from the original source not only add network latency, but it will also add data processing time.
2.4. Reduce Network Load
When we getting data from the cache, it also helps us reduce network load. As we mentioned earlier,cached data is stored locally or on a cache server, which does not need any additional processing of data, thus reducing the network load as we don’t need to transmit the data over the network. Modern application comprises a lot of components on different part of the network and getting data each time from the original server can add significant load on the network.
2.5. System Performance
Since caching reduce the number of times the data is loaded from the original server, it will improve the system performance by reducing
- Reduce network latency.
- Reduce origin source load.
- No need to process data as a response will be picked from cache directly.
3. Cache Hit Ratio
Before we move in more details, there is one important aspect which we should learn while talking about Cache in system design. Cache Hit Ratio is the most important key when we talk about caching and its effectiveness. Cache is only effective when the reuse of the same cache response is high. Higher cache hit ratio indicates a better working cache. Here is an example of the same:

There are three main factors that controls or drive the cache hit ratio
- Data set Size – data size stored in the cache.
- Cache storage size – Small cache size can lead to frequent cache overflow.
- Cache Invalidation time or longevity.
Let’s take a closer look at each component to understand how they affect the cache hit ratio:
3.1. Cache Data Set Size
Cache is like a key-value data storage very similar to HashMap. The cache key identified each object stored in the cache. There is no additional calculation needed to check if the key exists in the cache. We need to perform an exact cache key matching. Let’s take an example of an eCommerce application where we want to store product information in the cache. We can use the product id as cache key to store the information in the cache. Cache data set or key space indicates the number of cache key our application can generate. More unique cache keys your application generates, the less chance you have to reuse.
3.2 Cache Storage Size
Second major factor while calculating cache hit ratio is the number of item we can store in the cache before its full or have no space to add any new data. This is directly linked to the avg size of the object we are storing in the cache and the cache total size, if we are storing large objects in the cache, it will have a lesser number of objects and might run out of space soon while a good or optimum object size can increase the number of items being stored in the cache. If there is a high object replacement (cache eviction we will learn later) happening in the cache, you might see a low cache hit ratio.
The more item we can put in cache, the better is the overall cache hit ratio for our application.
3.3. Cache Longevity
The last item on the list is cache longevity. This shows for how long, on average, an object can continue to be in the cache before it expired or removed from the cache. We configure predefined time called Time to Live (TTL) which tells the caching system for how long an object can continue to be in the cache before it’s ready for removal. We will talk about these eviction policies in more details in next section.
4. Types of Caching
There are different caching that can be implemented based on the use cases. Let’s look at some of the mainstream caching types.
4.1. In-memory caching
This is the most commonly used caching. In-memory caching creates a caching area in the main memory of the computer, also known as RAM. As we all know in memory access is way faster than disk-based access (SSDs or HDDs). Some of the common use cases for In-memory caching are:
- Caching API response.
- HTML caching
- HTTP Session data
We can create a simple In-memory cache by using a simple Map or can use some third-party libraries like Redis or Memcached, etc.

4.2. Distributed In-memory Cache
It’s an extension to the In-memory cache. For distributed cache, we will have a separate cache servers such as Redis or Memcached to store the caching and all servers will read and write from these caching servers. It’s a central caching location which store and manages the cache and every application should use these caching servers for cache operations.
4.3. Disk Caching
As name suggested, disk caching stores the cache data on the disk. It’s slower than In-memory caching, however you can still scale the application since we don’t need to pull the data from remote server or APIs. It’s a good candidate where we want to store a large amount of data in the cache and In-memory caching may not be a good fit for it. Many Caching API’s work on the Hybrid mode where they store the primary or frequent data in the memory while other data is stores on the disk. Database-based query or caching is a good example of disk caching, though many systems now support In-memory caching as well for improved performance.
4.4. CDN Caching
CDN or content delivery network cache the data on distributed network of servers. CDN is now becoming a web standard and is a useful caching technique to reduce the load on our servers. There are multiple benefits of using CDN caching strategies.
- It reduce the load on the network.
- Save network bandwidth.
- Improve load time and customer experience.
CDN works by pushing the cache content closer to the user location and thus allow to server cached results from the closest cache location, this helps improve network latency. Some of the most common content which can be cached in the CDN are
- CSS.
- JavaScript files.
- Images
- Video images

4.5. DNS Caching
Cache used in the Domain Name System (DNS) for caching DNS queries. As we know, the server is mapped to IP addresses and they don’t understand the DNS name (e.g. www.google.com is DNS). To get the site data, we need the server IP where the site is hosted, when a user type domain name (e.g. www.google.com) in the address bar, the browser sends a query to the DNS server to get the server IP based on the domain name. Once the DNS server finds the IP, they respond with the IP address and the browser will use the IP to fetch the website data from the server. DNS caching helps speed up the site loading process, as without IP , the browser can’t get the data.
When the DNS server gets request, it checks in the local cache if the IP exists for a domain, if IP exists, it sends it immediately without checking any additional details. If you have ever worked on the site optimization, you must be familiar with the terms and DNS lookup time. A good DNS server will have a very low response time, showing they have deployed a good caching strategy at their end.
4.6. Browser / Client Cache
This is the first level of cache built in all modern browsers called browser cache. All modern browsers come with build in caching layer to reduce the number of request sent to the original servers. Browser use 2 level of caching layers
- In-memory cache.
- Local file based caching
Before any request sent to the original server, browser check local cache for a valid version and if a valid version exists in the local cache, the browser will reuse that without sending request to the original server.
5. Cache Eviction Policy
Cache is a temporary data storage and we need to remove the data from time to time to ensure other high usage items can be added to the cache. Let’s look at some of the well-known cache eviction policies.
5.1. First In First Out (FIFO)
FIFO policy works by removing the oldest item from the cache in case the cache is full. First In First Out gives priority to the new cache items over old entities. When the cache is full, it will discard the oldest items from the cache to make space for the new items.
5.2. Least Frequently Used (LFU)
As name suggested, this cache eviction policy will remove the least frequently used items when the cache is full. In such cache policy, items a total access count is maintained and once the cache is full, any item at the lowest count is cache queue will be removed to make space for the new item.
5.3. LRU – Least Recently Used
LRU cache eviction policy will remove the least recently used items when the cache is full. In such cache policy, items are pushed to the cache front as soon as they are used and once the cache is full, any item at the end of the cache queue will be removed to make space for the new item.
5.4. Last In First Out (LIFO)
LIFO prioritizes newer items over the old item. When the cache reaches its capacity and a new item needs to be added, LIFO removes the item that was added to the cache most recently.
5.5. Random Replacement (RR)
I think the name is self explanatory, when the cache is full, it will randomly select an item for eviction and will make space to new item.

6. Cache Invalidation
We talked about different aspects of caching in system design and how they can be used during our system design interview. Although caching provides us the tool to scale our system, make it fast but we also need to make sure the caching data is coherent with the source of truth (e.g. underlying data-source which contains original data.). We should have a way to update the cache as soon as the data in the underlying system is updated. This is very critical to avoid serving wrong or invalid data to the users.
Although caching invalidation seems easy since we simply removing the objects from the cache as soon as the data in the original source is changes, however cache invalidation will become difficult once our application expands. One of the main complexities in cache invalidation is when the cache objects represent underlying multiple data-sources, whenever any of these data
sources changes, you should invalidate all the cached objects that have used it as input. Let’s look at some of the popular data invalidation strategies.
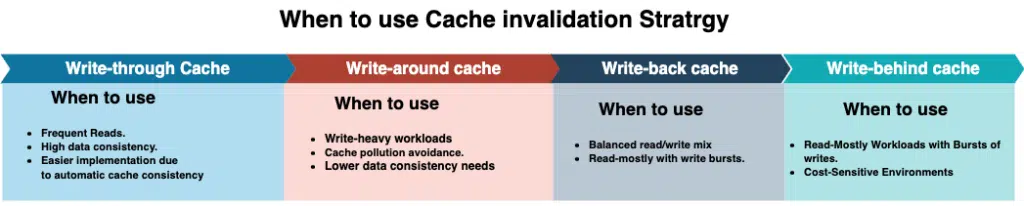
6.1. Write-through cache
With the Write-through cache, the data is added to both cache and the main data source at the same time. One of the main advantages is the data consistency between cache and database since we writing data on both systems simultaneously, it also simplifies the process. Another advantage is the fast retrial / response time for the next call and data is already available in the cache and no extra call is needed to get the data from the original data source. This can also ensure the Data durability in case there is a system failure as we have the data copy in 2 places.
Main drawback with Write-through cache is the multiple write operation, with this approach each write operation needs to ensure that data is added to both places before marking it as success. Here are some other disadvantages.
- Slower write as we need to write in 2 places.
- Overhead – Need more resources because of additional write operations.
- It can be a bottleneck, especially in high write volume application.

6.2. Write-around cache
Very similar to the Write-through cache, but we will write the data directly to the underlying data storage and not through cache. With Write-around cache, the cache system will check the underlying data source for data validity. This can help us solve the issue of extra write operation as we saw in Write-through cache. As you might have guessed, this will lead to cache miss and read latency for the first request sent by the application user. Once the first request is complete, all other requests will be served from cache until the item is removed from the cache. Also, this can lead to data inconsistencies issues, especially when multiple users are changing the same data.

6.3. Write-back cache
With the Write-back cache, the system will write the data to cache and give a success signal to the application. The cache API handles sync the data back to the original source through an asynchronous process. Here are some benefits:
- Improve write performance since the data is only written to cache layer before sending success signal.
- It can improve the system performance by not overloading the main data source and let cache layer write it asynchronously to the main data source.
Some drawbacks for using Write-back cache are
- It can lead to data inconsistency, as data is not immediately available in the main data source.
- Add a complexity on the cache layer for data consistency between cache and the main data source.

6.4. Write-behind cache
Very close to what Write-back cache is but Write-behind cache works on the eventual consistency. As soon as the data is written to the cache, it sends a success signal to the client however the data is not immediately added the queue as seen in the Write-back but will eventually be written to the original cache.
Choosing a cache invalidation strategy is very tricky and we need to clearly understand the trade-off while we choose and discuss the strategy in our system design. Based on the type of application we are designing, the strength of the type of invalidation strategy can become a bottleneck.
7. Cache Invalidation Methods
In the previous section, we talked about cache invalidation and what are different cache invalidation strategies are . This section will focus on the main method used for cache invalidation.
7.1. Purge Method
This is a common method used to purge/update the cache content in the caching layer, which is no longer valid. Content is removed as soon as caching API receives purging request for a content and the cache will be updated when the next request for the content is received. We can have the following 2 types of purging request.
- Purge specific cache object, URLs.
- Purge entire cache (purge everything)
7.2. Refresh
As the name suggests, the refresh call will receive, the cache content is updated with the latest copy from the original server. It’s opposite to what the purge method does since it will only replace the cache content but will update / refresh it.
7.3. Time-to-live (TTL)
This is the most common terms you might hear when working on the caching. The Time-to-live (TTL) indicates the time value for the item in cache, after which the cache value will be marked as invalid or stale and should be refreshed. While the cache API is serving the content from cache, it always checks the TTL and only serve the content if they are still valid else cache API will get the latest content and refresh the cache content as well.
8. Distributed Cache
Although we will cover this in more details during our distributed system cache design lesson, however there are 2 ways we can set up distributed cache.
- Cache on individual server in the cluster.
- As a cluster outside of the individual application server.
The first one is simple, as the cache region is created within each application server in the cluster. Each machine maintains its own cache. One of the main disadvantage for this approach is the chances of cache data going out of sync from other application server in the cluster causing issues.
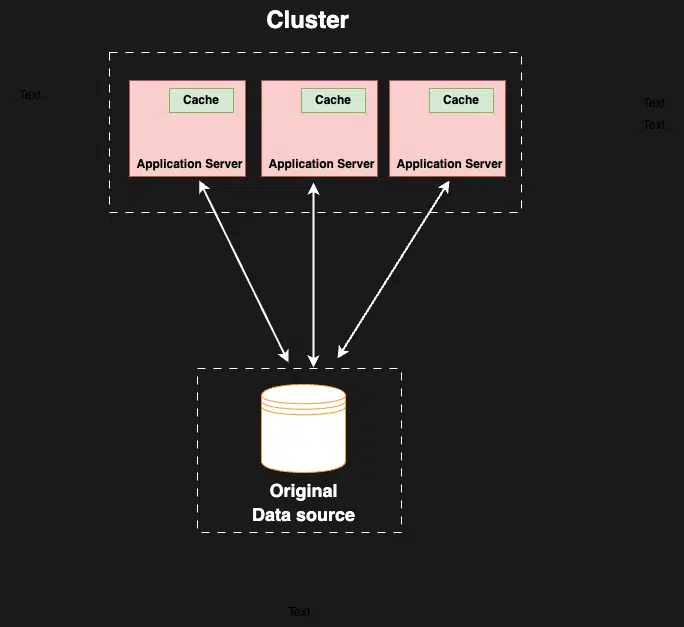
A shared cache cluster is outside of the application server and manages its own cache layer.
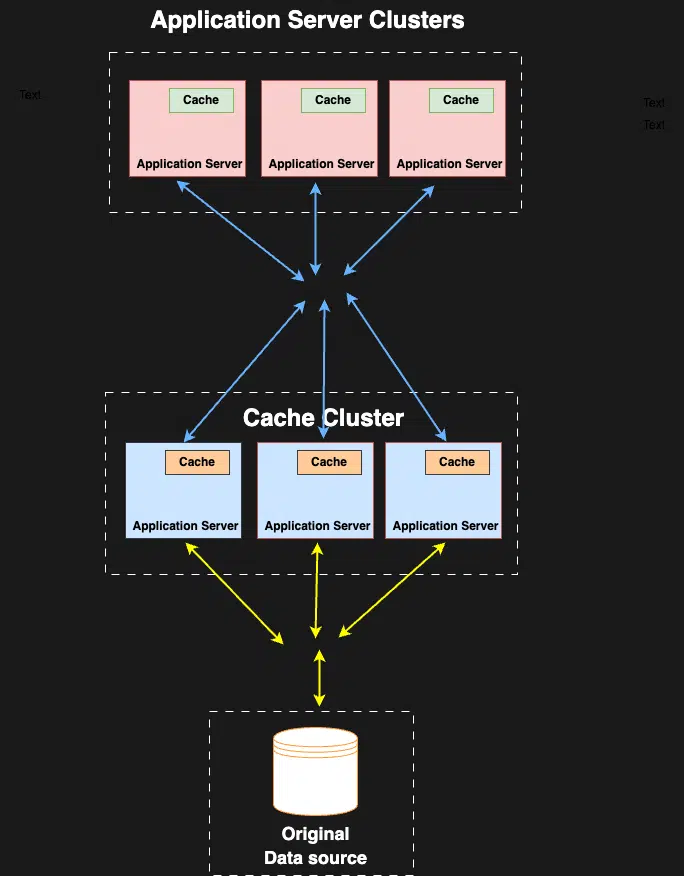
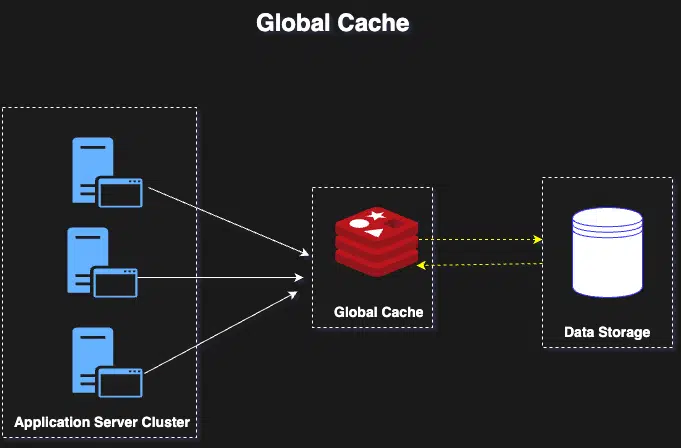
9. Global Cache
Global cache is a single shared cache layer, which is used by all application servers or the application using this cache layer. All requests go to the global cache to get the data, in case data is found in the cache, it will be returned else cache layer will get the data from the original data source.Global caches can significantly improve application performance by reducing the load on the original data source and minimizing database calls.
10. When not to use Caching
Although caching looks really promising and it’s a great tool when comes to system scaling and throughput optimization, however Caching isn’t a perfect solution for every situation and we should consider these cases while decided to use caching.
- Frequently Changing Data: If the data is being changed frequently (e.g. product stock in commerce applications) , we should not cache such data. Caching such data requires a lot of efforts to ensure caching data is in sync with original source and can soon override the caching benefits.
- Less Frequently used Data: If your data is rarely used, avoid using caching for these cases as we will end up using the caching space for no benefits. Remember, caching has a large cost implication than using other storage options like disk or file storage.
- Applications with Consistency Requirement: If you are working on an application which requires high data Consistency (e.g. banking or financial applications), avoid using caching.
- Personalized Data: We should try to avoid storing personalized data like user profile etc. in the cache.
Summary
As we understood, caching is a very useful tool for working on system optimization and performance. Having a clear understanding of different caching strategies with its benefits can help you a lot during your system design interviews. With modern distributed application, caching is taking a more central stage, especially in system performance and reducing latency.
I hope this article provides you with some good understanding about caching in system design. If you have any feedback, please provide your feedback. As always, you can explore our GitHub repository to get the latest code.