Consistent Hashing is a core technique to scale up your application and an important concept for System Design Interviews. It’s a core strategy in your system design and used in almost all the system design interview questions. A good understanding of the Consistent Hashing will ensure that you are well aware of the main areas while designing your application.
What You will learn?
1. Consistent Hashing
Consistent hashing is one of the techniques used to achieve the scalability while working on the application, especially the storage of the data. It helps us to achieve the horizontal scaling. As we know, horizontal scaling helps us distribute the data efficiently and evenly across multiple servers. Before we dive in to the details on consistent hashing, let’s look at the problem in hand.
1.1. Why Consistent Hashing?
Let’s assume that we are building an application and one of the goal is to scale the application to handle million / billion of customers. To scale application for such a huge customer base, we may need n number of database for our application (We can’t store all data in 1 Database server). This is how our application high level architecture will look like:
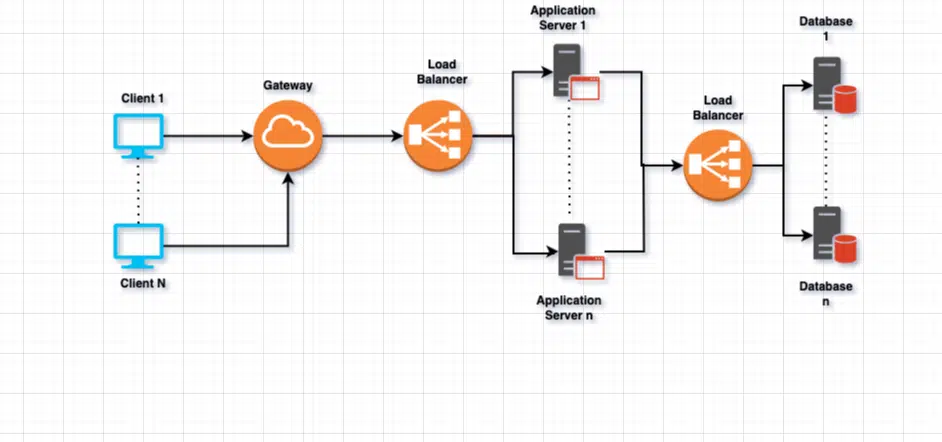
Let’s see what are some of the main goal while designing our scalable and distributed database
- We should be able to store the data uniformly among the n data base servers.
- Incoming queries should be distributed uniformly among our n database servers. We should not be in a situation where 1 server is serving or storing a lot of data than others.
- We need to have the flexibility to add or remove database servers dynamically. This is a very common trait or any scalable solution where we can add / remove resources based on the demand.
- When we remove or add database servers, we should move only a few data around the servers. Think about a solution where we need to move entire data if we add / remove a node. That will not be acceptable since the application will not be available during this activity.
1.2. Hash Based Solution
So our simple requirement is to accept any incoming request (either to store to get the data) and send this to a specific server. One of the key point is to ensure which server store the data when a read request is coming since we can’t afford to go through every database server to check the key. A simple solution is to use the hash function as follows:
- Create a hash of the incoming request by using a hash function like
hashVal = hashFun(key);. - Get the server index by calculating the modulo
("%")of the hashValue with the number of servers
server = hashVal % N // N is the number of database servers.Let’s look at the following example of how this will work:
- Let’s assume we have 4 servers.
- We run each key through our
hashfunctionand calculate the modulo("%")to see which server the key is stored or should be stored. Here is how we can do thathash(key) % N. - If the output of #2 is 1, it should be stored on the server 1 and if the output is 4 , its on server 4.
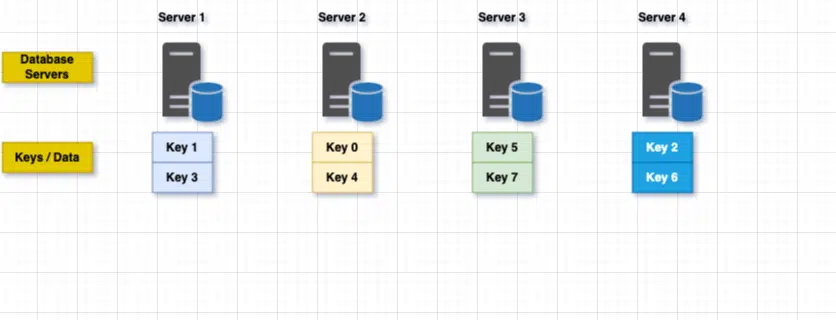
Do you think this is a good solution and works for us? Well, this approach works great when we have a fixed number of servers in the pool. There are 2 major problems with this when we talk about scalability and data uniformity.
2. Horizontal Scaling
Our above approach is not horizontal scalable. Remember, one of the core aspects of any scalable solution is the horizontal scaling. What happens when we add or remove a database server? If we do that, the existing mapping will be broken as the modulo ("%") will start giving a different server index for most of the keys. Although the hash function will still give us the same key but when we do the modulo ("%"), we get a different index. We have the following 2 options if we add or remove a database server.
- We need to re-map all the data once a new server is added or any existing server is removed.
- System might be down during this activity or we might serve wrong data to our customers.
2.1. Adding a new server
Let’s take this case where we have to add a new server since the existing servers are growing rapidly and we may need to offload some load from other servers.
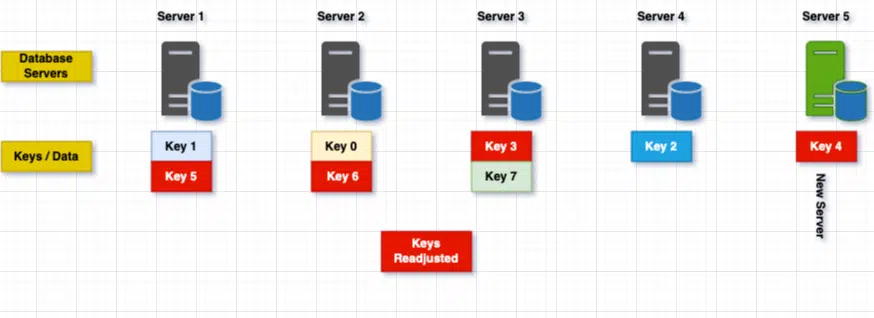
As visible in the above screen, when we added a new server, over 75% of the keys were rearranged, which is not good especially when we talking about a lot of databases. This is more drastic when we remove database server or say it goes offline.
2.2 Removing Server
When a server goes offline or we have to remove it, the new index will be clattered as hash(key)% N. In our case, it will become (key)% 3
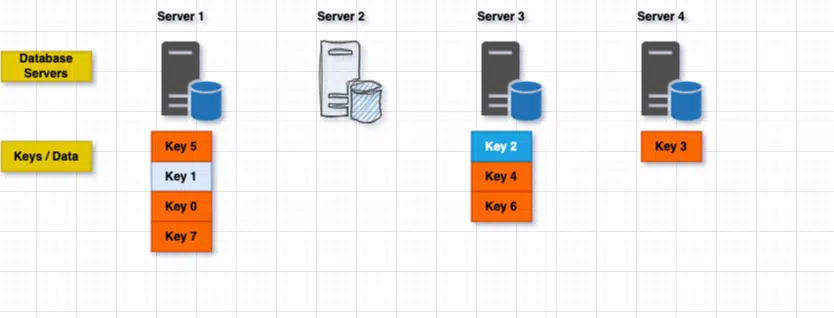
As we can see, once the server goes offline, most of the keys were redistributed, so if we don’t take any action, many times we will get a wrong server index for a key
3. Consistent Hashing to Rescue
To help us in horizontal scaling and ensure a minimum redistribution happens, we can use consistent hashing to help us. Consistent hashing is a special kind of hashing such that when a hash table is re-sized and consistent hashing is used, only k/n keys need to be remapped on average, where k is the number of keys, and n is the number of slots [Wikipedia]. Let’s see how consistent hashing works and how it will help us minimize the re-mapping/ reorganization of data when nodes are added or removed.
3.1 How Consistent Hashing Works?
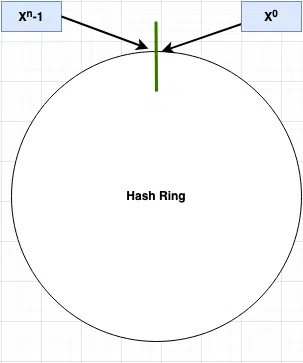
Let’s assume we use a hash function (say SHA1 etc.) to that generate a integer hash range say x0, x1, x2….xn. Let’s say this range is between 0 to 232 -1. We can put this in an array of integer something like
| 0 | 1 | … | … | 232-1 |
Now lets image this integer array was put on a ring such as the last and the first value wrap around and form a ring. By collecting both ends, we get a hash ring as:
3.2 Hash Servers
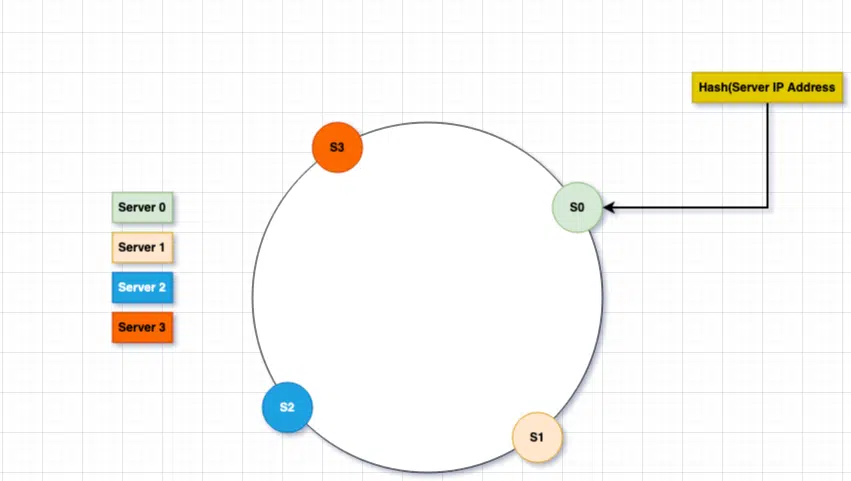
Our next task is to place these database servers on the given ring. We have a list of servers and we will put them in the ring as we described above. We will use the hash function to map the given server on the ring. To calculate the hash, we can use server IP address or name as the input parameter. Here is an example where we place the 4 server on the hash ring.
3.3 Key Placement On Servers
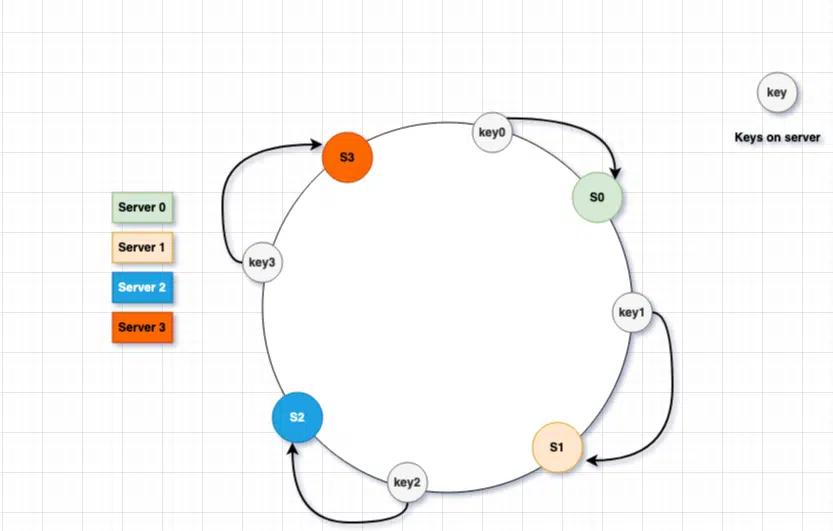
Let’s see how do we determine where a given key / data in the ring will be stored.
- The key will go through the same hash function we used to place the server on the hash ring.
- Once we have the hash, it can be used to map the key in some position on the hash ring. There can be 2 cases when we have the hash and try to place the data on the hash ring.
- If the hash value position map directly to the server position, we place the key on the given database server.
- If the hash value position on the ring does not have a database server, we start going clockwise direction and insert the key once we find the first data base server moving in the clockwise direction.
Let’s look at the following screen to understand how the placement of the key work in this. In our example, all the keys are not in the same place as the database server, so we start going clockwise direction and assigned the key to the first server found on the ring.
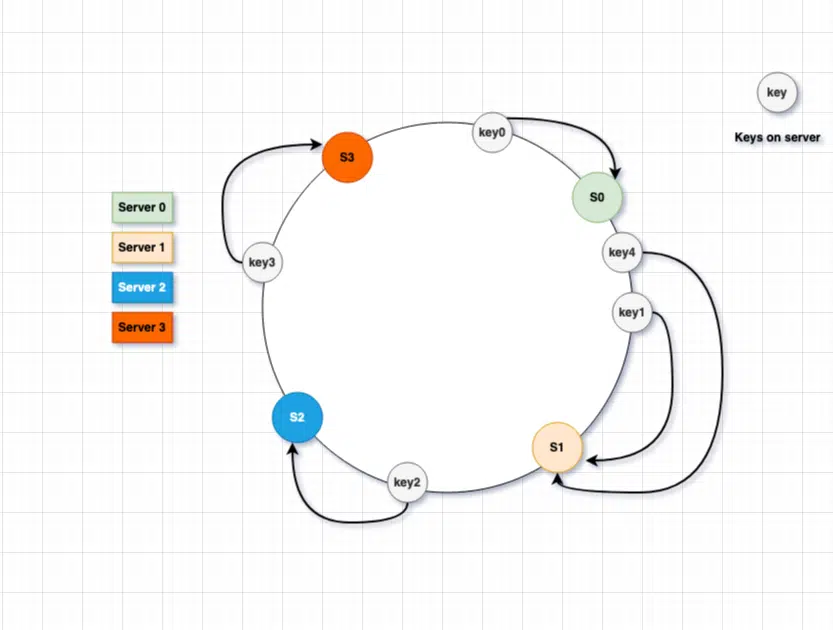
Here is another example where over 1 key is mapped to the same database server on the ring.
One challenge in our first design was to reassign all the key if we add / remove a database server. Let’s see how this works when we add a new database server in the hash ring.
3.4. Add a Server
Adding a new database server to the ring will affect only a few keys and we only require redistributing fractions of keys. Let’s add another server 4 to the ring and see what is the overall impact of adding this new server.
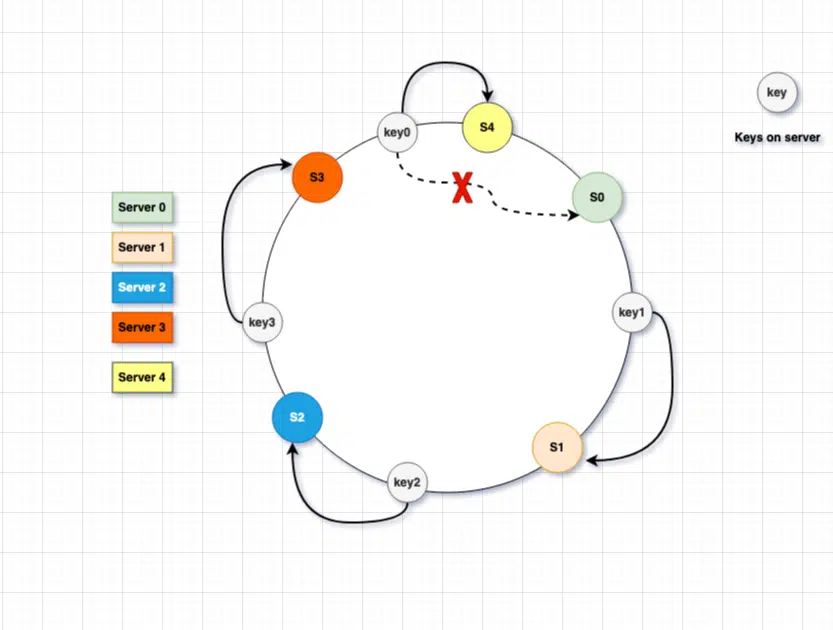
As visible in the image, when we added a new database server 4 in the hash ring, only the key 0 was redistributed. The key0 was removed from the s0 and reassigned to S4 as it’s the first server in the ring when we go clockwise, starting from our key0 location.
On an average , we’ll need to remap only k/n keys , where k is the number of keys and n is the number of servers.
3.5 Remove a Server
In a distributed system, there is always a possibility that server is going offline either because of some failure or we may no longer need that amount of infrastructure (part of cloud scaling), consistent hashing will ensure that server removed will cause a less amount of impact on the system and we should only redistribute a few sets of keys. Let’s see what will happen if our <em>server1</em> is removed.
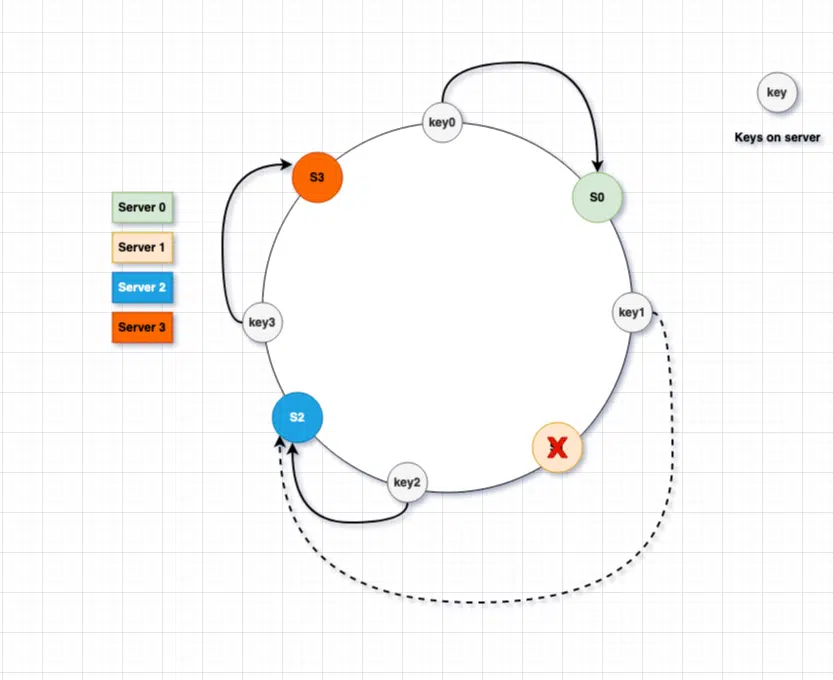
As we can see, when S1 goes offline, only they key1 was reassigned to the S2 while all other keys were unaffected by this.
There are few issues with the above approach which we should address:
- As we can add and remove the server on the fly, it’s impossible to keep the same size of partition on the ring. There is always a possibility that a single server might have a large chunk of keys assigned as compared to the other servers.
Let’s take this example where one server(s1) was removed from the ring and, as we can see from image, the s2 partition is twice as large than s0 and s3
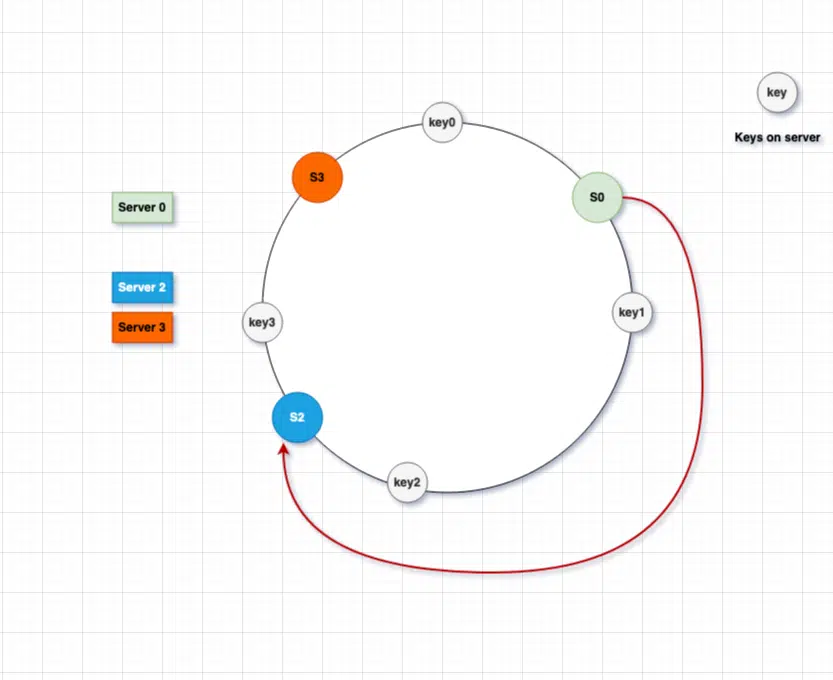
Also, as we can see, the keys are non uniformly distributed. S0 has 2 keys while S2 and S3 only have 1 key each and there is always a possibility that new key might be added in the S0 again making is more non uniform distribution. Here are some of the issue we might face when adding or removing the virtual nodes.
- Adding or removing nodes: Adding or removing nodes will cause recomputing the tokens, causing a significant administrative overhead for a large cluster.
- Hotspots: Since each node is assigned one large range, if the data is not evenly distributed, some nodes can become hotspots.
- Node rebuilding: Since each node’s data might be replicated (for fault-tolerance) on a fixed number of other nodes, when we need to rebuild a node, only its replica nodes can provide the data. This puts a lot of pressure on the replica nodes and can lead to service degradation.
How Do we resolve this problem of non uniformity and make sure keys are distributed uniformly?
4. Virtual Nodes
There is a simple solution to resolve this issue by adding a number of replicas, also known as virtual nodes or Vnodes. Think of virtual nodes and real nodes and each server is represented by multiple virtual nodes on the ring. Let’s look at the following pictures:
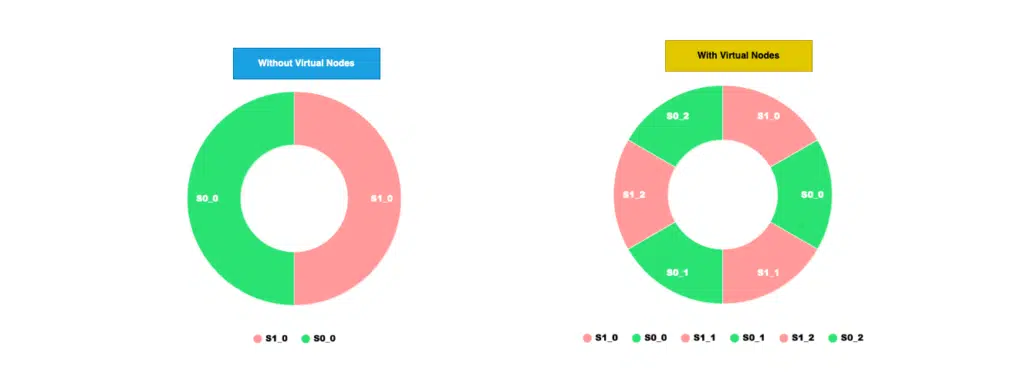
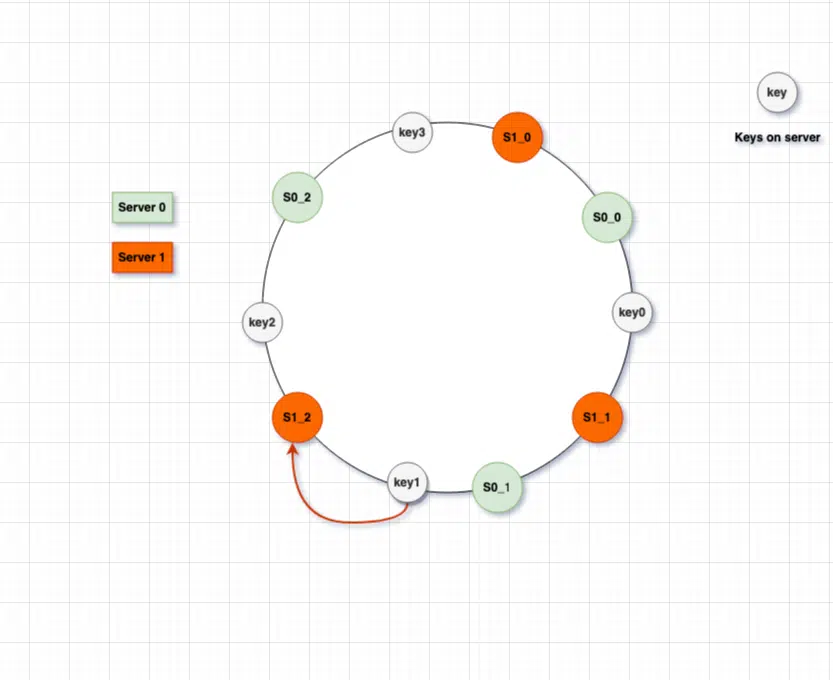
Virtual Nodes are the real nodes and each server is represented by multiple virtual nodes on the hash ring. As we can see in the above picture, before the virtual nodes, each server S0 and S1 have a fixed range but once we have the virtual nodes in the system, instead of say S1 , we have S1_0, S1_1 and S1_2 representing the S1. Each server in this case is managing multiple partitions (e.g Partition marked as S0 and managed by S0 server ).
Vnodes are randomly distributed across the cluster and are non-contiguous so that no two neighboring Vnodes are assigned to the same physical node. Nodes also carry replicas of other nodes for fault tolerance. To find the key in the virtual nodes setup, we go again clockwise and pick the first node, matching our criteria. In order to find the key1, we go clockwise from key1 and find the virtual node S1_2 which is our Server1.
Here are some additional benefits of using Virtual nodes in consistent hashing.
- As Vnodes help spread the load more evenly across the physical nodes on the cluster by dividing the hash ranges into smaller sub-ranges.
- It decrease the chances for 1 machine being a hotspot by assigning small ranges to each node. It will avoid the one big range being assigned to a single node.
5. Consistent Handing and System Design Interview
Consistent hashing is a way of dividing data evenly across multiple servers, like putting files into different folders. This is useful for large systems that need to handle a lot of data, like online stores or social networks. Consistent hashing makes it easy to add or remove servers without disrupting the system. It also makes sure that data is always stored in the same place, even if the servers are rearranged.
Here are some examples of how consistent hashing is used:
- An online store might use consistent hashing to store product images across multiple servers. This would make it easy to add more servers if the store becomes more popular.
- A social network might use consistent hashing to store user profiles across multiple servers. This would make sure that all the user profiles are always available, even if some servers are down.
- A content delivery network (CDN) might use consistent hashing to store copies of websites across multiple servers around the world. This would make sure that users can always access websites quickly, no matter where they are located.
Summary
We covered a lot about consistent hashing in this post. We get a good understanding of why we need consistent hashing and how it works. In fact, we broadly covered the following items:
- It helps us to scale the nodes horizontally.
- It makes it easy to add and remove nodes without affecting all the keys. This is very important for large distributed systems with a lot of data.
- Help us mitigate hotspot key problem where 1 server might become overloaded.
Here are some of the popular system where this is used in real life
- Apache Casandra : Use to partition data across clusters.
- Discord Chat.
- Amazon Dynamo DB.
- All popular CDN (e.g Akamai)
I really hope this lesson provides you a good understanding of consistent hashing and its use in the system design interview. Feel free to provide your feedback in the comment section. As always, you can explore our GitHub repository to get the latest code and run it locally.